kafka集群搭建
#
- 1 规划
- 2 Zookeeper集群准备
- 3 安装包准备
- 4 安装
- 4.1 解压
- 4.2 配置环境变量
- 4.3修改server.properties
- 4.4 同步Kafka安装目录
- 5 启动集群
- 5.1 启动zookeeper集群
- 5.2 启动 Kafka集群
- 6 测试
- 6.1创建主题
- 6.2 创建生产者
- 6.3 创建消费
- 6.4 动态消费
- 6.5 查看消费者偏移量
1 规划
准备4台虚拟机,规划如下
| 主机 | node0 | node0 | node2 | node3 |
|---|---|---|---|---|
| 节点 | ZooKeper | ZooKeper | ZooKeper | |
| 节点 | Kafka | Kafka | Kafka |
2 Zookeeper集群准备
Zookeeper集群搭建详见hadoop基于zookeper自动高可用搭建 中7 zookeper 安装。
3 安装包准备
官网下载地址:http://kafka.apache.org/downloads.html。本实例下载版本为kafka\_2.10-0.9.0.1。下载后上传到node0上。
4 安装
4.1 解压
在node0上将安装包解压
tar -xvf kafka_2.10-0.9.0.1.tgz -C /opt/app/
4.2 配置环境变量
在 etc/profile 中添加KAFKA_HOME
vim etc/profileexport KAFKA_HOME=/opt/app/kafka_2.10-0.9.0.1export PATH=$PATH:$KAFKA_HOME/bin
保存后 使profile 生效
source /ect/profile
在node1 和node2上做同样的操作
4.3修改server.properties
vim /opt/app/kafka_2.10-0.9.0.1/config/server.propertiesbroker.id-0zookeeper.connect=node1:2181,node2:2181,node3:2181
核心配置参数说明:
broker.id: broker集群中唯一标识id,0、1、2、3依次增长(broker即Kafka集群中的一台服务器)
4.4 同步Kafka安装目录
将当前node0服务器上的Kafka目录同步到其他node1、node2服务器上:
scp -r kafka_2.10-0.9.0.1* node1:`pwd`scp -r kafka_2.10-0.9.0.1* node2:`pwd`
同步完成后
修改 node1和node2上 server.properties 中broker.id
node2中broker.id
5 启动集群
5.1 启动zookeeper集群
在node1 node2 node3 启动zookeeper集群
zkServer.sh start
5.2 启动 Kafka集群
先在node0上启动,在kafka安装目录下
kafka-server-start.sh config/server.properties

启动后再node4 上观察集群状态
zkCli.shls /brokers/ids/0
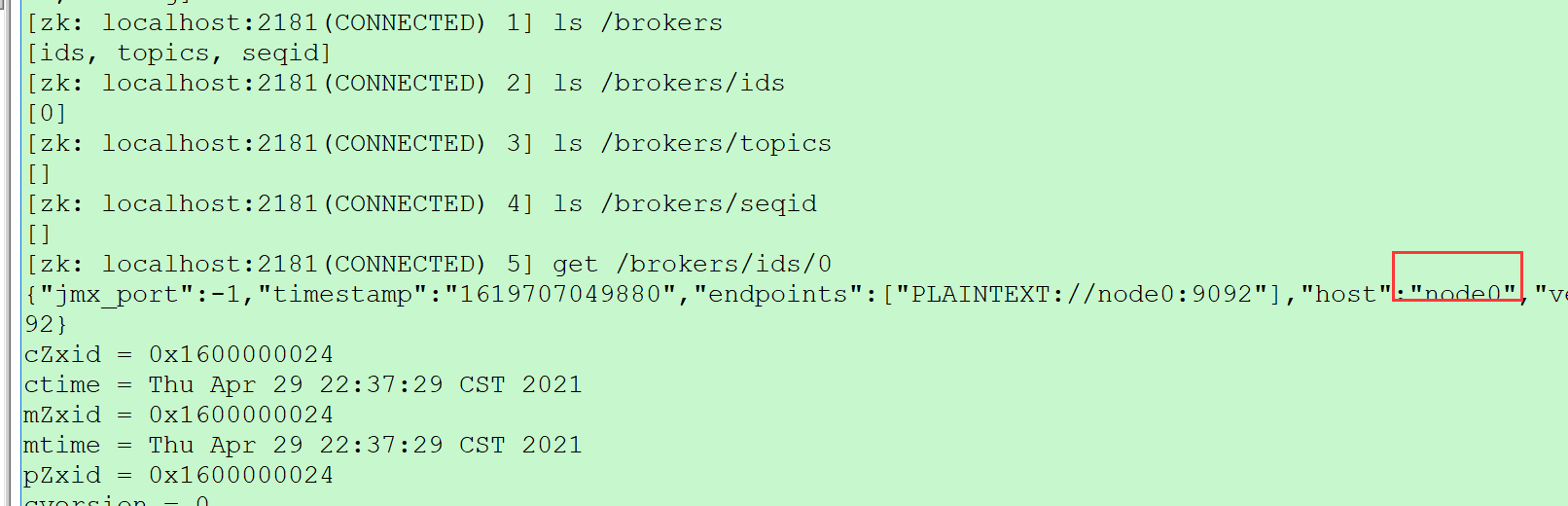
启动 node1上kafka服务器
kafka-server-start.sh config/server.properties
在zk中观察集群节点
node2上启动kafka
在zk中可以看到集群状态
6 测试
6.1创建主题
创建主题 mytest 有三个分区 ,每个分区有2个副本
以及主题test1 有三个分区 ,每个分区有1个副本
kafka-topics.sh --create --partitions 3 -replication-factor 2 --topic mytest --zookeeper node1:2181,node2:2181,node3:2181kafka-topics.sh --create --partitions 3 --replication-factor 1 --topic test1 --zookeeper node1:2181,node2:2181,node3:2181
参数说明:
–replication-factor:指定每个分区的复制因子个数,默认1个
–partitions:指定当前创建的kafka分区数量,默认为1个
–topic:指定新建topic的名称
查看主题
kafka-topics.sh --zookeeper node1:2181 --list

查看主题描述
kafka-topics.sh --zookeeper node3:2181 --describe --topic test1kafka-topics.sh --zookeeper node3:2181 --describe --topic mytest


6.2 创建生产者
kafka-console-producer.sh --broker-list node0:9092,node1:9092,node2:9092 --topic test1hello1hello2
输入 hello1 …………hello9 ctrl+c 后退出
6.3 创建消费
kafka-console-consumer.sh --zookeeper node1:2181 --from beginning --topic test1

6.4 动态消费
再打开连接一个ssh node0 并创建生产者
kafka-console-producer.sh --broker-list node0:9092,node1:9092,node2:9092 --topic test1
可以动态生产数据,然后下面的消费者会继续消费数据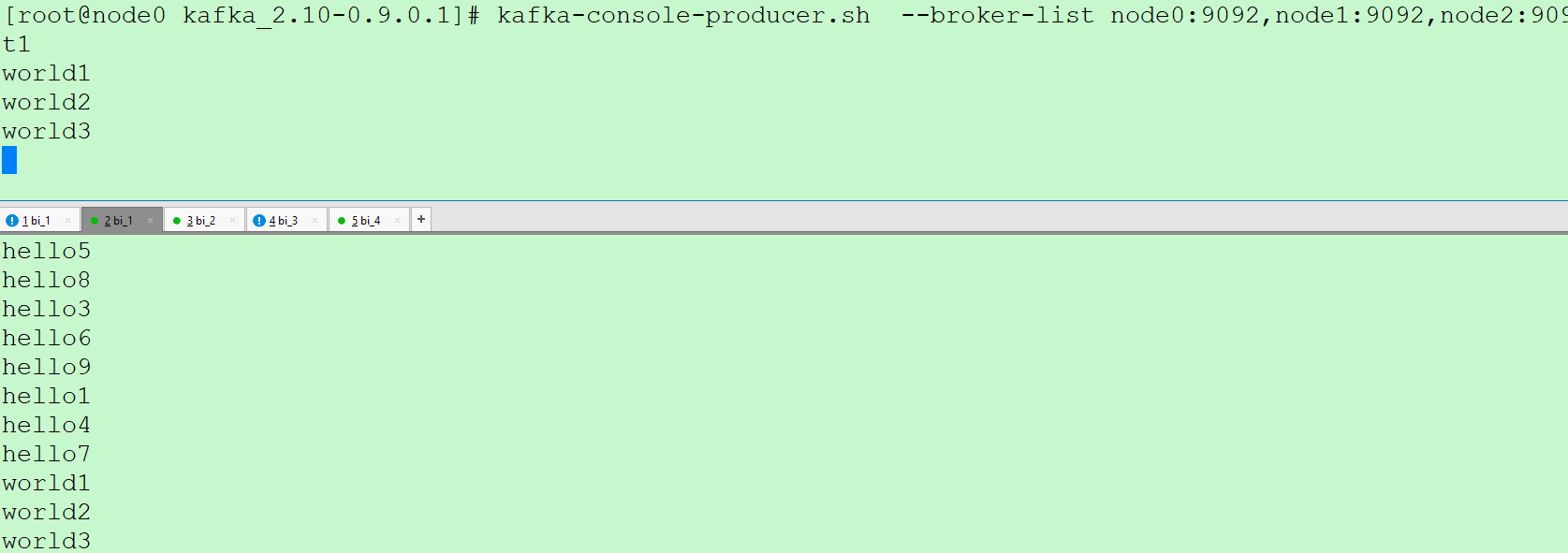
6.5 查看消费者偏移量
查看某个消费者的偏移量(zookeeper中查看)
get /consumers/console-consumer-43384/offsets/test1/0 0号分区偏移量get /consumers/console-consumer-43384/offsets/test1/1 1号分区偏移量get /consumers/console-consumer-43384/offsets/test1/2 2 号分区偏移量


























 —— 一个窗口显示多张图片")








还没有评论,来说两句吧...