Kafka集群搭建
一,环境准备
\* Zookeeper单点/集群服务(演示单点使用单点, 演示集群使用集群)\* kafka安装包-- kafka\_2.11-1.1.0.tgz\* 自己玩, 基于虚拟机搭建
二,Kafka单点搭建
1,安装Zookeeper安装包,可以参考之前Zookeeper集群搭建,不做赘述2,上传解压kafka安装包到指定目录tar -zxvf kafka_2.11-1.1.0.tgz -C /usr/develop/3,修改./conf/server.properties配置文件,修改zookeeper链接地址为真实地址zookeeper.connect=192.168.91.131:21814,启动zookeeper服务,启动前切记关闭防火墙或者开放服务端口(zk:2181;kafka:9092)// 关闭防火墙service iptables stop// 启动zookeeper服务sh ./bin/zkServer.sh start// 查看zookeeper服务状态sh ./bin/zkServer.sh status5,kafka关联server.properties配置信息启动,&表示后台启动sh kafka-server-start.sh ../config/server.properties &

6,查看kafka启动状态,存在进程,说明启动成功ps -ef | grep kafka
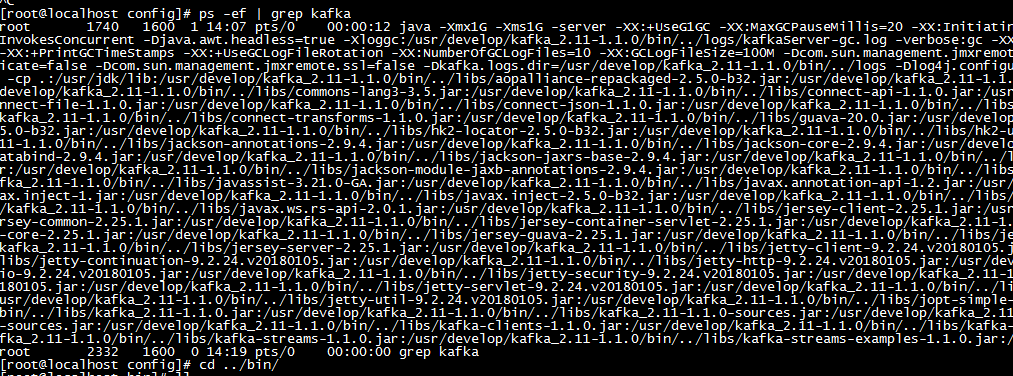
7,添加topic,下列命令表示在zookeeper服务上添加名称为“standloneTest”的topic\* --partitions 2 :表示该话题存在两个分区,不指定默认使用(num.partitions配置信息),分区数用于限制对Consumer并行数的限制,Consumer并行数不能大于partition分区数,若超出则分配完分区后,其他Consumer轮空\* --replication-factor 1 : 表示每个分区存在一个副本,不指定默认使用(default.replication.factor),具体含义下一篇分析sh kafka-topics.sh --create --zookeeper 192.168.91.131:2181 --replication-factor 1 --partitions 2 --topic standloneTest8,kafka日志文件查看节点状态\* 日志文件路径,在server.properties中配置,下列演示为默认路径演示log.dirs=/tmp/kafka-logs\* 查看日志文件
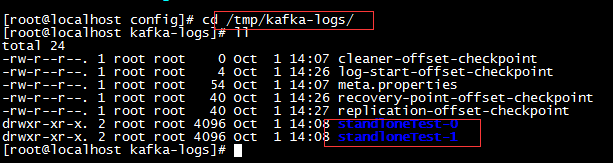
\* 从上图可以看出,话题standloneTest创建成功,且成功构造出两个分区-0和分区-19,zookeeper节点查看topic信息
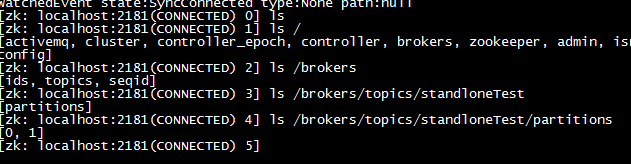
\* 从zookeeper节点可以看出, 跟节点下创建了需要支撑kafka的一系列节点,\* /brokers节点下存在当前kafka节点的topic信息集合,\* 进入/brokers/topics节点,可以看到该节点上存储上的所有topic,进入创建的topic : standardTest\* 进入/brokers/tipics/standardTest节点,可以看到当前topic主题的分区信息,该topic分为两个分区,则节点下有0和1两个分区,其中展示的0和1每个分区,表示该分区在该broker节点下的副本,用于集群中数据同步\* 获取分区状态信息,如下,具体分区详情信息在集群搭建中再做详解
10,kafka常用命令//kafka后台启动命令sh ./bin/kafka-server-start.sh -daemon ../config/server.properties// kafka停止命令,sh ./bin/kafka-server-stop.sh// 创建topic命令sh ./bin/kafka-topics.sh --create --zookeeper 192.168.91.131:2181 --replication-factor 1 --partitions 2 --topic standloneTest// 查看topic列表sh ./bin/kafka-topics.sh --list --zookeeper 192.168.91.131:2181// 修改topicsh ./bin/kafka-topics.sh --alert --zookeeper 192.168.91.131:2181 --partitions 1 --topic myTest// 查看topic信息sh ./bin/kafka-topics.sh --describe --zookeeper 192.168.91.131:2181 --topic myTest// 删除topicsh ./bin/kafka-topics.sh --delete --zookeeper 192.168.91.131:2181 --topic myTest// 控制台生产者sh ./bin/kafka-console-producer.sh --broker-list 192.168.91.131:9092 --topic myTest// 控制台消费者sh ./bin/kafka-console-consumer.sh --zookeeper 192.168.91.131:2181 --from-beginning --topic myTest
三,Kafka集群搭建
1,环境准备\* zookeeper集群环境\* 三台虚拟机作为服务器搭载kafka2,修改./conf/server.properties配置文件\* 修改zookeeper链接zookeeper.connect=192.168.91.128:2181,192.168.91.129:2181,192.168.91.130:2181\* 修改broker.id(默认值为0),三台broker.id不一致,broker.id=1broker.id=2broker.id=3\* 修改listeners,修改为当前IPlisteners=PLAINTEXT://192.168.91.128:90923,逐节点启动zookeeper集群和kafka集群,链接zookeeper查询节点信息,三个broker在注册中心全部注册成功

4,基于集群模式创建topic,创建三个分区,每个分区上创建三个副本。保证每个分区的Leader副本可以分布在三台机器上,并且在另外两台机器上分别创建一个Follower副本sh kafka-topics.sh --create --zookeeper 192.168.91.129:2181,192.168.91.129:2181,192.168.91.130:2181 --replication-factor 3 --partitions 3 --topic clusterTest5,在日志文件查看分区副本信息,可以看到该服务器下有三个分区的信息,其中一个分区的副本信息为三个副本信息的Leader副本,其余两个分区的副本信息为该分片的Follower副本;副本存在目的主要用于实现数据同步,且副本详情信息存储在zookeeper节点
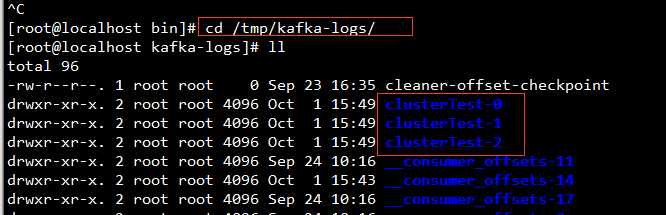
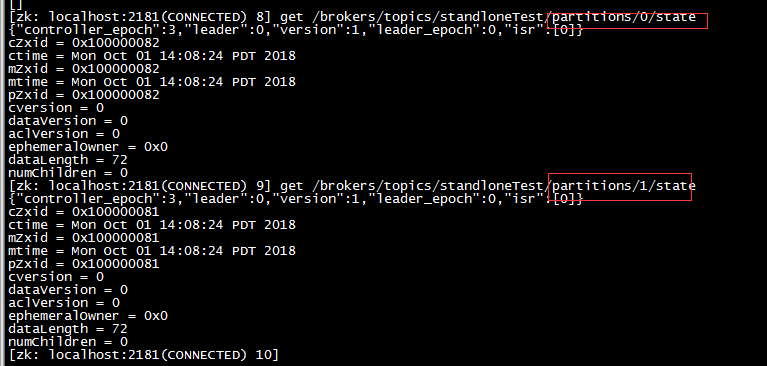
6,在zookeeper客户端查看副本详情\* 查看副本信息详情命令get /brokers/topics/clusterTest/partitions/0/state

\* 节点信息分析-- leader : 标识当前分区的Leader副本所在的broker.id-- leader\_epoch : 同zookeeper集群leader选举的epoch概念,标识当前Leader的版本号-- isr : 当前集群下的分片副本信息集合,随着集群信息变化,该isr值动态变更-- Leader副本所在broker宕机后,会触发Leader重新选举,leader\_epoch加1
四,Java连接Kafka集群进行消息处理
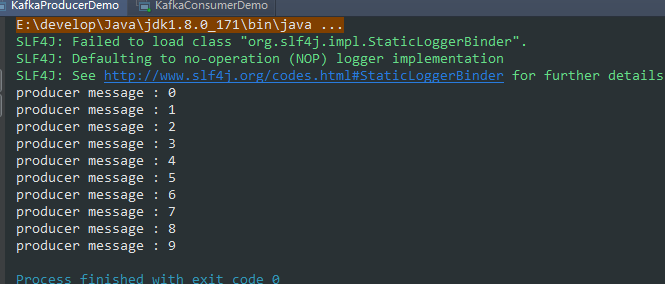
1,服务端发送消息public class KafkaProducerDemo extends Thread {private final KafkaProducer<Integer, String> producer;private final String topic;public KafkaProducerDemo(String topic) {Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.129:9092,192.168.91.129:9092,192.168.91.130:9092");properties.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo");properties.put(ProducerConfig.ACKS_CONFIG, "-1");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");producer = new KafkaProducer<Integer, String>(properties);this.topic = topic;}@Overridepublic void run() {for (int i = 0; i < 10; i++) {String message = "producer message : " + i;System.out.println(message);producer.send(new ProducerRecord<Integer, String>(topic, message));try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) {KafkaProducerDemo producerDemo = new KafkaProducerDemo("clusterTest");producerDemo.start();}}
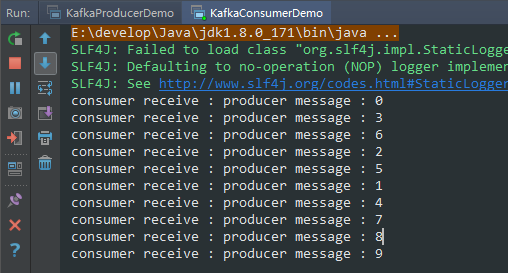
2,客户端消费消息public class KafkaConsumerDemo extends Thread {private final KafkaConsumer<String, Integer> kafkaConsumer;public KafkaConsumerDemo(String topic) {Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.91.129:9092,192.168.91.129:9092,192.168.91.130:9092");properties.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerDemo");properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");// 从第一个顺序读取properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");kafkaConsumer = new KafkaConsumer<String, Integer>(properties);kafkaConsumer.subscribe(Collections.singleton(topic));}@Overridepublic void run() {while (true) {ConsumerRecords<String, Integer> consumerRecords = kafkaConsumer.poll(1000);for (ConsumerRecord record : consumerRecords) {System.out.println("consumer receive : " + record.value());}}}public static void main(String[] args) {KafkaConsumerDemo consumerDemo = new KafkaConsumerDemo("clusterTest");consumerDemo.start();}}

























(sink端)")
")

使用 Kibana 操作 ES")





还没有评论,来说两句吧...