动态规划
动态规划的设计思想
动态规划(DP)[1]通过分解成子问题解决了给定复杂的问题,并存储子问题的结果,以避免再次计算相同的结果。我们通过下面这个问题来说明这两个重要属性:重叠子问题和最优子结构。
重叠子问题
像分而治之,动态规划也把问题分解为子问题。动态规划主要用于:当相同的子问题的解决方案被重复利用。在动态规划中,子问题解决方案被存储在一个表中,以便这些不必重新计算。因此,如果这个问题是没有共同的(重叠)子问题, 动态规划是没有用的。例如,二分查找不具有共同的子问题。下面是一个斐波那契函数的递归函数,有些子问题被调用了很多次。
/* simple recursive program for Fibonacci numbers */int fib(int n){if ( n <= 1 )return n;return fib(n-1) + fib(n-2);}
执行 fib(5) 的递归树
fib(5)/ \fib(4) fib(3)/ \ / \fib(3) fib(2) fib(2) fib(1)/ \ / \ / \fib(2) fib(1) fib(1) fib(0) fib(1) fib(0)/ \fib(1) fib(0)
我们可以看到,函数f(3)被称执行2次。如果我们将存储f(3)的值,然后避免再次计算的话,我们会重新使用旧的存储值。有以下两种不同的方式来存储这些值,以便这些值可以被重复使用。
- 记忆化(自上而下)
- 打表(自下而上)
记忆化(自上而下):
记忆化存储其实是对递归程序小的修改,作为真正的DP程序的过渡。我们初始化一个数组中查找所有初始值为零。每当我们需要解决一个子问题,我们先来看看这个数组(查找表)是否有答案。如果预先计算的值是有那么我们就返回该值,否则,我们计算该值并把结果在数组(查找表),以便它可以在以后重复使用。
下面是记忆化存储程序:
/* Memoized version for nth Fibonacci number */#include<stdio.h>#define NIL -1#define MAX 100int lookup[MAX];/* Function to initialize NIL values in lookup table */void _initialize(){int i;for (i = 0; i < MAX; i++)lookup[i] = NIL;}/* function for nth Fibonacci number */int fib(int n){if(lookup[n] == NIL){if ( n <= 1 )lookup[n] = n;elselookup[n] = fib(n-1) + fib(n-2);}return lookup[n];}int main (){int n = 40;_initialize();printf("Fibonacci number is %d ", fib(n));getchar();return 0;}
打表(自下而上)
下面我们给出自下而上的打表方式,并返回表中的最后一项。
/* tabulated version */#include<stdio.h>int fib(int n){int f[n+1];int i;f[0] = 0; f[1] = 1;for (i = 2; i <= n; i++)f[i] = f[i-1] + f[i-2];return f[n];}int main (){int n = 9;printf("Fibonacci number is %d ", fib(n));getchar();return 0;}
这两种方法都能存储子问题解决方案。在第一个版本中,记忆化存储只在查找表存储需要的答案。而第二个版本,所有子问题都会被存储到查找表中,不管是否是必须的。比如LCS问题的记忆化存储版本,并不会存储不必要的子问题答案。
最优子结构[2]
如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。最优子结构性质为动态规划算法解决问题提供了重要线索。
例如,最短路径问题有以下最优子结构性质:如果一个节点x是到源节点ü的最短路径,同时又是到目的节点V的最短路径,则最短路径从u到v是结合最短路径:u到x和x到v。解决任意两点间的最短路径的算法的Floyd-Warshall算法[3]和贝尔曼-福特[4]是动态规划的典型例子。
另一方面最长路径问题不具有最优子结构性质。这里的最长路径是指两个节点之间最长简单路径(路径不循环)。
考虑下算法导论上面的例子:
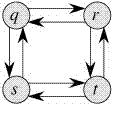
有两条最长的路径与Q到T:Q – > R – > T和Q – > S-> T。不像最短路径,这些路径最长不具有最优子属性。例如,最长路径q-> r-> t不是由q->r 和 r->t的组合 ,因为最长的路径从q至r为q-> s-> t->r
动态规划算法的设计要素
这里用一个矩阵链乘问题为例说明动态规划算法的设计要素。
例如:给定n个矩阵{ A1,A2,…,A**n},其中A**i与A**i+1是可乘的,i=1,2,…,n−1。考察这n个矩阵的连乘积A1A2…A**n。由于矩阵乘法满足结合律,故计算矩阵的连乘积可以有许多不同的计算次序,这种计算次序可以用加括号的方式来确定。若一个矩阵连乘积的计算次序完全确定,则可以依此次序反复调用2个矩阵相乘的标准算法(有改进的方法,这里不考虑)计算出矩阵连乘积。若A是一个p×q矩阵,B是一个q×r矩阵,则计算其乘积C=AB的标准算法中,需要进行pqr次数乘。
例如,如果我们有四个矩阵A,B,C和D,我们将有:
(A**B)C=A(B**C)=(A**C)B=….
不同组合得到的运算次数是不同的,例如A为 10 × 30 , B为 30 × 5 , C 为 5 × 60 ,那么,如果采用第一种次序,执行的基本运算次数是:
(AB)C = (10×30×5) + (10×5×60) = 1500 + 3000 = 4500
而采用第二种次序,执行的基本运算次数是:
A(BC) = (30×5×60) + (10×30×60) = 9000 + 18000 = 27000
很明显第一种运算更为高效。
问题:给定一个数组P[]表示矩阵的链,使得第i个矩阵Ai 的维数为 p[i-1] x p[i].。我们需要写一个函数MatrixChainOrder()返回这个矩阵连相乘最小的运算次数。
示例:
输入:P [] = {40,20,30,10,30}输出:26000有4个矩阵维数为 40X20,20X30,30×10和10X30。运算次数最少的计算方式为:(A(BC))D - > 20 * 30 * 10 +40 * 20 * 10 +40 * 10 * 30输入:P[] = {10,20,30,40,30}输出:30000有4个矩阵维数为 10×20,20X30,30X40和40X30。运算次数最少的计算方式为:((AB)C)D - > 10 * 20 * 30 +10 * 30 * 40 +10 * 40 * 30
最优子结构:
一个简单的解决办法是把括号放在所有可能的地方,计算每个位置的成本,并返回最小值。对于一个长度为n的链,我们有n-1种方法放置第一组括号。
例如,如果给定的链是4个矩阵。让矩阵连为ABCD,则有3种方式放第一组括号:A(BCD),(AB)CD和(ABC)D。
所以,当我们把一组括号,我们把问题分解成更小的尺寸的子问题。因此,这个问题具有最优子结构性质,可以使用递归容易解决。
2)重叠子问题
以下是递归的实现,只需用到上面的最优子结构性质。
//直接的递归解决#include<stdio.h>#include<limits.h>//矩阵 Ai 的维数为 p[i-1] x p[i] ( i = 1..n )int MatrixChainOrder(int p[], int i, int j){if(i == j)return 0;int k;int min = INT_MAX;int count;// 在第一个和最后一个矩阵直接放置括号//递归计算每个括号,并返回最小的值for (k = i; k <j; k++){count = MatrixChainOrder(p, i, k) +MatrixChainOrder(p, k+1, j) +p[i-1]*p[k]*p[j];if (count < min)min = count;}return min;}// 测试int main(){int arr[] = {1, 2, 3, 4, 3};int n = sizeof(arr)/sizeof(arr[0]);printf("Minimum number of multiplications is %d ",MatrixChainOrder(arr, 1, n-1));getchar();return 0;}
上面直接的递归方法的复杂性是指数级。当然可以用记忆化存储优化。应当指出的是,上述函数反复计算相同的子问题。请参阅下面的递归树的大小4的矩阵链。函数MatrixChainOrder(3,4)被调用两次。我们可以看到,有许多子问题被多次调用。
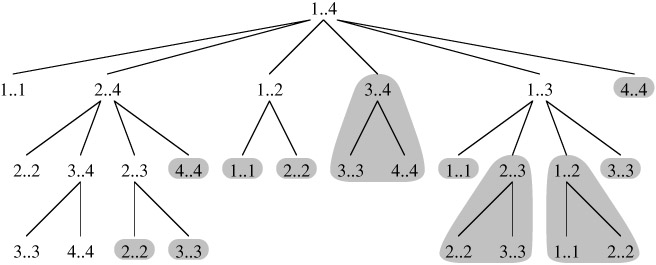
动态规划解决方案
以下是C / C + +实现,使用动态规划矩阵链乘法问题。
#include<stdio.h>#include<limits.h>int MatrixChainOrder(int p[], int n){/* 第0行第0列其实没用到 */int m[n][n];int i, j, k, L, q;//单个矩阵相乘,所需数乘次数为0for (i = 1; i < n; i++)m[i][i] = 0;//以下两个循环是关键之一,以6个矩阵为例(为描述方便,m[i][j]用ij代替)//需按照如下次序计算//01 12 23 34 45//02 13 24 35//03 14 25//04 15//05//下面行的计算结果将会直接用到上面的结果。例如要计算14,就会用到12,24;或者13,34等等for (L=2; L<n; L++){for (i=1; i<=n-L+1; i++){j = i+L-1;m[i][j] = INT_MAX;for (k=i; k<=j-1; k++){q = m[i][k] + m[k+1][j] + p[i-1]*p[k]*p[j];if (q < m[i][j])m[i][j] = q;}}}return m[1][n-1];}int main(){int arr[] = {1, 2, 3, 4};int size = sizeof(arr)/sizeof(arr[0]);printf("Minimum number of multiplications is %d ",MatrixChainOrder(arr, size));getchar();return 0;}
时间复杂度: O(n3)
空间复杂度: O(n2)
动态规划算法典型的应用
最长递增子序列LIS
最长递增子序列LIS[5]的问题可以使用动态规划要解决的问题,例如,最长递增子序列(LIS)的问题是要找到一个给定序列的最长子序列的长度,使得子序列中的所有元素被排序的顺序增加。例如,{10,22,9,33,21,50,41,60,80} LIS的长度是6和 LIS为{10,22,33,50,60,80}。
1) 最优子结构
对于长度为N的数组A[N]={ a0,a1,a2,…,a**n−1},假设假设我们想求以aj结尾的最大递增子序列长度,设为L[j],那么L[j] = max(L[i]) + 1, where i < j && a[i] < a[j], 也就是i的范围是0到j – 1。这样,想求aj结尾的最大递增子序列的长度,我们就需要遍历j之前的所有位置i(0到j-1),找出a[i] < a[j],计算这些i中,能产生最大L[i]的i,之后就可以求出L[j]。之后我对每一个A[N]中的元素都计算以他们各自结尾的最大递增子序列的长度,这些长度的最大值,就是我们要求的问题——数组A的最大递增子序列。
2) 重叠子问题
以下是简单的递归实现LIS问题(先不说性能和好坏,后面讨论)。这个实现我们遵循上面提到的递归结构。使用 max_ending_here 返回 每一个LIS结尾的元素,结果LIS是使用指针变量返回。
/* LIS 简单的递归实现 */#include<stdio.h>#include<stdlib.h>/* 要利用递归调用,此函数必须返回两件事情:1) Length of LIS ending with element arr[n-1]. We use max_ending_here for this purpose2) Overall maximum as the LIS may end with an element before arr[n-1] max_ref is used this purpose.The value of LIS of full array of size n is stored in *max_ref which is our final result*/int _lis( int arr[], int n, int *max_ref){/* Base case */if(n == 1)return 1;int res, max_ending_here = 1; // 以arr[n-1]结尾的 LIS的长度/* Recursively get all LIS ending with arr[0], arr[1] ... ar[n-2]. Ifarr[i-1] is smaller than arr[n-1], and max ending with arr[n-1] needsto be updated, then update it */for(int i = 1; i < n; i++){res = _lis(arr, i, max_ref);if (arr[i-1] < arr[n-1] && res + 1 > max_ending_here)max_ending_here = res + 1;}// Compare max_ending_here with the overall max. And update the// overall max if neededif (*max_ref < max_ending_here)*max_ref = max_ending_here;// Return length of LIS ending with arr[n-1]return max_ending_here;}// The wrapper function for _lis()int lis(int arr[], int n){// The max variable holds the resultint max = 1;// The function _lis() stores its result in max_lis( arr, n, &max );// returns maxreturn max;}/* 测试上面的函数 */int main(){int arr[] = { 10, 22, 9, 33, 21, 50, 41, 60 };int n = sizeof(arr)/sizeof(arr[0]);printf("Length of LIS is %d\n", lis( arr, n ));getchar();return 0;}
根据上面的实现方式,以下是递归树大小4的调用。LIS(N)为我们返回arr[]数组的LIS长度。
lis(4)/ | \lis(3) lis(2) lis(1)/ \ /lis(2) lis(1) lis(1)/lis(1)
我们可以看到,有些重复的子问题被多次计算。所以我们可以使用memoization (记忆化存储)的或打表 来避免同一子问题的重新计算。以下是打表方式实现的LIS。
/* LIS 的动态规划方式实现*/#include<stdio.h>#include<stdlib.h>/* lis() returns the length of the longest increasing subsequence inarr[] of size n */int lis( int arr[], int n ){int *lis, i, j, max = 0;lis = (int*) malloc ( sizeof( int ) * n );/* Initialize LIS values for all indexes */for ( i = 0; i < n; i++ )lis[i] = 1;/* Compute optimized LIS values in bottom up manner */for ( i = 1; i < n; i++ )for ( j = 0; j < i; j++ )if ( arr[i] > arr[j] && lis[i] < lis[j] + 1)lis[i] = lis[j] + 1;/* Pick maximum of all LIS values */for ( i = 0; i < n; i++ )if ( max < lis[i] )max = lis[i];/* Free memory to avoid memory leak */free( lis );return max;}/* 测试程序 */int main(){int arr[] = { 10, 22, 9, 33, 21, 50, 41, 60 };int n = sizeof(arr)/sizeof(arr[0]);printf("Length of LIS is %d\n", lis( arr, n ) );getchar();return 0;}
注意,上面动态的DP解决方案的时间复杂度为O(n2),其实较好的解决方案是O(nlogn)
最长公共子序列LCS
LCS问题[6] [7]描述:给定两个序列,找出在两个序列中同时出现的最长子序列的长度。一个子序列是出现在相对顺序的序列,但不一定是连续的。例如,“ABC”,“ABG”,“BDF”,“AEG”,“acefg“,..等都是”ABCDEFG“ 序列。因此,长度为n的字符串有2n个不同的可能的序列。
注意:
最长公共子串(Longest CommonSubstring)和最长公共子序列(LongestCommon Subsequence, LCS)的区别:子串(Substring)是串的一个连续的部分,子序列(Subsequence)则是从不改变序列的顺序,而从序列中去掉任意的元素而获得的新序列;更简略地说,前者(子串)的字符的位置必须连续,后者(子序列LCS)则不必。比如字符串acdfg同akdfc的最长公共子串为df,而他们的最长公共子序列是adf。LCS可以使用动态规划法解决。
这是一个典型的计算机科学问题,基础差异(即输出两个文件之间的差异文件比较程序),并在生物信息学有较多应用。例如:输入序列“ABCDGH”和“AEDFHR” 的LCS是“ADH”长度为3;输入序列“AGGTAB”和“GXTXAYB”的LCS是“GTAB”长度为4。
这个问题的直观的解决方案是同时生成给定序列的所有子序列,找到最长匹配的子序列。此解决方案的复杂性是指数的。让我们来看看如何这个问题 (拥有动态规划(DP)问题的两个重要特性):
1)最优子结构:
设输入序列是X[0..m−1]和Y[0..n−1],长度分别为m和n。和设序列L(X[0..m−1],Y[0..n−1])是这两个序列的LCS的长度。
以下为L(X[0..M−1],Y[0..N−1])的递归定义:
- 如果两个序列的最后一个元素匹配(即X [M-1] == Y [N-1])
L(X[0..M−1],Y[0..N−1])=1+L(X[0..M−2],Y[0..N−1]) - 如果两个序列的最后字符不匹配(即X [M-1]!= Y [N-1])
L(X[0..M−1],Y[0..N−1])=MAX(L(X[0..M−2],Y[0..N−1]),L(X[0..M−1],Y[0..N−2])
例:
1)考虑输入字符串“AGGTAB”和“GXTXAYB”。最后一个字符匹配的字符串。这样的LCS的长度可以写成:
L(“AGGTAB”, “GXTXAYB”) = 1 + L(“AGGTA”, “GXTXAY”)
2)考虑输入字符串“ABCDGH”和“AEDFHR。最后字符不为字符串相匹配。这样的LCS的长度可以写成:
L(“ABCDGH”, “AEDFHR”) = MAX ( L(“ABCDG”, “AEDFHR”), L(“ABCDGH”, “AEDFH”) )
因此,LCS问题有最优子结构性质!
2)重叠子问题:
以下是直接的递归实现, 遵循上面提到的递归结构。
/* 简单的递归实现LCS问题 */#include<stdio.h>#include<stdlib.h>int max(int a, int b);/* Returns length of LCS for X[0..m-1], Y[0..n-1] */int lcs( char *X, char *Y, int m, int n ){if (m == 0 || n == 0)return 0;if (X[m-1] == Y[n-1])return 1 + lcs(X, Y, m-1, n-1);elsereturn max(lcs(X, Y, m, n-1), lcs(X, Y, m-1, n));}/* Utility function to get max of 2 integers */int max(int a, int b){return (a > b)? a : b;}/* 测试上面的函数 */int main(){char X[] = "AGGTAB";char Y[] = "GXTXAYB";int m = strlen(X);int n = strlen(Y);printf("Length of LCS is %d\n", lcs( X, Y, m, n ) );getchar();return 0;}
上面直接的递归方法的时间复杂度为O(2n).(在最坏的情况下。X和Y不匹配的所有字符即LCS的长度为0)。按照到上述的实现,下面是对输入字符串“AXY**T”和“AYZ**X”的部分递归树:
lcs("AXYT", "AYZX")/ \lcs("AXY", "AYZX") lcs("AXYT", "AYZ")/ \ / \lcs("AX", "AYZX") lcs("AXY", "AYZ") lcs("AXY", "AYZ") lcs("AXYT", "AY")
在上述部分递归树,LCS(“AXY”,“AYZ”)被调用两次。如果我们绘制完整的递归树,那么我们可以看到,我们可以看到很多重复的调用。所以这个问题有重叠的子结构性质,可使用memoization的或打表来避免重新计算。下面是用动态规划(打表)解决LCS问题:
/ *动态规划实现的LCS问题* /#include<stdio.h>#include<stdlib.h>int max(int a, int b);/* Returns length of LCS for X[0..m-1], Y[0..n-1] */int lcs( char *X, char *Y, int m, int n ){int L[m+1][n+1];int i, j;/* Following steps build L[m+1][n+1] in bottom up fashion. Notethat L[i][j] contains length of LCS of X[0..i-1] and Y[0..j-1] */for (i=0; i<=m; i++){for (j=0; j<=n; j++){if (i == 0 || j == 0)L[i][j] = 0;else if (X[i-1] == Y[j-1])L[i][j] = L[i-1][j-1] + 1;elseL[i][j] = max(L[i-1][j], L[i][j-1]);}}/* L[m][n] contains length of LCS for X[0..n-1] and Y[0..m-1] */return L[m][n];}/* Utility function to get max of 2 integers */int max(int a, int b){return (a > b)? a : b;}/*测试上面的函数 */int main(){char X[] = "AGGTAB";char Y[] = "GXTXAYB";int m = strlen(X);int n = strlen(Y);printf("Length of LCS is %d\n", lcs( X, Y, m, n ) );getchar();return 0;}
最长回文子序列
问题[8]:给一个字符串,找出它的最长的回文子序列的长度。例如,如果给定的序列是“BBABCBCAB”,则输出应该是7,“BABCBAB”是在它的最长回文子序列。 “BBBBB”和“BBCBB”也都是该字符串的回文子序列,但不是最长的。注意和最长回文子串的区别(参考:最长回文串)!这里说的子序列,类似最长公共子序列LCS( Longest Common Subsequence)问题,可以是不连续的。这就是LPS(Longest Palindromic Subsequence)问题。
最直接的解决方法是:生成给定字符串的所有子序列,并找出最长的回文序列,这个方法的复杂度是指数级的。下面来分析怎么用动态规划解决。
1)最优子结构
假设 X[0 … n-1] 是给定的序列,长度为n. 让 L(0,n-1) 表示 序列 X[0 … n-1] 的最长回文子序列的长度。
- 如果X的最后一个元素和第一个元素是相同的,这时:L(0,n−1)=L(1,n−2)+2 , 还以 “BBABCBCAB” 为例,第一个和最后一个相同,因此 L(1,n-2) 就表示红色的部分。
- 如果不相同:L(0, n-1) = MAX ( L(1, n-1) , L(0, n-2) )。 以”BABCBCA” 为例,L(1,n-1)即为去掉第一个元素的子序列,L(0, n-2)为去掉最后一个元素。
有了上面的公式,可以很容易的写出下面的递归程序:
#include<stdio.h>#include<string.h>int lps(char *seq, int i, int j){//一个元素即为1if (i == j)return 1;if(i > j) return 0; //因为只计算序列 seq[i ... j]// 如果首尾相同if (seq[i] == seq[j])return lps (seq, i+1, j-1) + 2;// 首尾不同return max( lps(seq, i, j-1), lps(seq, i+1, j) );}/* 测试 */int main(){char seq[] = "acmerandacm";int n = strlen(seq);printf ("The lnegth of the LPS is %d", lps(seq, 0, n-1));getchar();return 0;}
Output: The lnegth of the LPS is 5 (即为: amama)
2) 重叠子问题
画出上面程序的递归树(部分),已一个长度为6 的字符串为例:
L(0, 5)/ \L(1,5) L(0,4)/ \ / \L(2,5) L(1,4) L(1,4) L(0,3)
可见有许多重复的计算,例如L(1,4)。该问题符合动态规划的两个主要性质: 重叠子问题 和 最优子结构 。下面通过动态规划的方法解决,通过自下而上的方式打表,存储子问题的最优解。
int lpsDp(char * str,int n){int dp[n][n], tmp;memset(dp,0,sizeof(dp));for(int i=0; i<n; i++) dp[i][i] = 1;// i 表示 当前长度为 i+1的 子序列for(int i=1; i<n; i++){tmp = 0;//考虑所有连续的长度为i+1的子串. 该串为 str[j, j+i]for(int j=0; j+i<n; j++){//如果首尾相同if(str[j] == str[j+i]){tmp = dp[j+1][j+i-1] + 2;}else{tmp = max(dp[j+1][j+i],dp[j][j+i-1]);}dp[j][j+i] = tmp;}}//返回串 str[0][n-1] 的结果return dp[0][n-1];}
该算法的时间复杂度为O(n2)。其实这个问题和 最长公共子序列 问题有些相似之处,我们可以对LCS算法做些修改,来解决此问题:
- 1) 对给定的字符串逆序 存储在另一个数组 rev[] 中
- 2) 再求这两个 字符串的 LCS的长度
时间复杂度也为O(n2)。
最小编辑距离(Edit Distance)
问题:给定一个长度为m和n的两个字符串,设有以下几种操作:替换(R),插入(I)和删除(D)且都是相同的操作。寻找到转换一个字符串插入到另一个需要修改的最小(操作)数量。
PS:最短编辑距离算法右许多实际应用,参考Lucene[9]的 API。另一个例子,对一个字典应用,显示最接近给定单词\正确拼写单词的所有单词。
找递归函数:
这个案例的子问题是什么呢?考虑寻找的他们的前缀子串的编辑距离,让我们表示他们为[1…i]和[1….j] , 1<i<m 和1<j<n.显然,这是解决最终问题的子问题,记为E(i,j)。我们的目标是找到E(m,n)和最小的编辑距离。
我们可以用三种方式:(i,−), (−,j)和(i,j)右对齐两个前缀字符串。连字符符号(–)表示没有字符。
看一个例子或许会更清楚:假设给定的字符串是 SUNDAY 和 SATURDAY。如果i=2 , j=4,即前缀字符串分别是SU和SATU(假定字符串索引从1开始)。这两个字串最右边的字符可以用三种不同的方式对齐:
- (i,j): 对齐字符U和U。他们是相等的,没有修改的必要。我们仍然留下其中i=1和j=3,即问题E(1,3)
- (i, -) : 对第一个字符串右对齐,第二字符串最右为空字符。我们需要一个删除(D)操作。我们还留下其中i = 1和j = 4的 子问题 E(i-1,j)。
- (-, j) : 对第二个字符串右对齐,第一个字符串最右为空字符。在这里,我们需要一个插入(I)操作。我们还留下了子问题i=2 和 j=3,E(i,j−1)。
对于这三种操作,我可以得到最少的操作为:
E(i,j)=min([E(i−1,j)+D],[E(i,j−1)+I],[E(i−1,j−1)+R])
其中,E(i−1,j−1)+R表示:如果 i,j 字符不一样.到这里还没有做完。什么将是基本情况?
当两个字符串的大小为0,其操作距离为0。当其中一个字符串的长度是零,需要的操作距离就是另一个字符串的长度. 即:
E(0,0)=0,E(i,0)=i,E(0,j)=j
为基本情况。这样就可以完成递归程序了。
动态规划解法:
我们先计算出上面递归表达式的时间复杂度:T(m,n)=T(m−1,n−1)+T(m,n−1)+T(m−1,n)+C. T(m,n)的复杂性,可以通过连续替代方法或结二元齐次方程计算。结果是指数级的复杂度。这是显而易见的,从递归树可以看出这将是一次又一次地解决子问题。
我们对重复子问题的结果打表存储,并在有需要时(自下而上)查找。动态规划的解法时间复杂度为 O(m**n) 正是我们打表的时间.通常情况下,D,I和R操作的成本是不一样的。在这种情况下,该问题可以表示为一个有向无环图(DAG)与各边的权重,并且找到最短路径给出编辑距离。
实现代码如下:
// 动态规划实现 最小编辑距离#include<stdio.h>#include<stdlib.h>#include<string.h>// 测试字符串#define STRING_X "SUNDAY"#define STRING_Y "SATURDAY"#define SENTINEL (-1)#define EDIT_COST (1)inlineint min(int a, int b) {return a < b ? a : b;}// Returns Minimum among a, b, cint Minimum(int a, int b, int c){return min(min(a, b), c);}// Strings of size m and n are passed.// Construct the Table for X[0...m, m+1], Y[0...n, n+1]int EditDistanceDP(char X[], char Y[]){// Cost of alignmentint cost = 0;int leftCell, topCell, cornerCell;int m = strlen(X)+1;int n = strlen(Y)+1;// T[m][n]int *T = (int *)malloc(m * n * sizeof(int));// Initialize tablefor(int i = 0; i < m; i++)for(int j = 0; j < n; j++)*(T + i * n + j) = SENTINEL;// Set up base cases// T[i][0] = ifor(int i = 0; i < m; i++)*(T + i * n) = i;// T[0][j] = jfor(int j = 0; j < n; j++)*(T + j) = j;// Build the T in top-down fashionfor(int i = 1; i < m; i++){for(int j = 1; j < n; j++){// T[i][j-1]leftCell = *(T + i*n + j-1);leftCell += EDIT_COST; // deletion// T[i-1][j]topCell = *(T + (i-1)*n + j);topCell += EDIT_COST; // insertion// Top-left (corner) cell// T[i-1][j-1]cornerCell = *(T + (i-1)*n + (j-1) );// edit[(i-1), (j-1)] = 0 if X[i] == Y[j], 1 otherwisecornerCell += (X[i-1] != Y[j-1]); // may be replace// Minimum cost of current cell// Fill in the next cell T[i][j]*(T + (i)*n + (j)) = Minimum(leftCell, topCell, cornerCell);}}// 结果存储在 T[m][n]cost = *(T + m*n - 1);free(T);return cost;}// 递归方法实现int EditDistanceRecursion( char *X, char *Y, int m, int n ){// 基本情况if( m == 0 && n == 0 )return 0;if( m == 0 )return n;if( n == 0 )return m;// Recurseint left = EditDistanceRecursion(X, Y, m-1, n) + 1;int right = EditDistanceRecursion(X, Y, m, n-1) + 1;int corner = EditDistanceRecursion(X, Y, m-1, n-1) + (X[m-1] != Y[n-1]);return Minimum(left, right, corner);}int main(){char X[] = STRING_X; // verticalchar Y[] = STRING_Y; // horizontalprintf("Minimum edits required to convert %s into %s is %d\n",X, Y, EditDistanceDP(X, Y) );printf("Minimum edits required to convert %s into %s is %d by recursion\n",X, Y, EditDistanceRecursion(X, Y, strlen(X), strlen(Y)));return 0;}
给出了动态规划实现 和 递归实现。大家可以比较他们的效率差异。
硬币找零问题
问题[10] [11]:假设有m种面值不同的硬币,个个面值存于数组S={ S1,S2,…S**m}中,现在用这些硬币来找钱,各种硬币的使用个数不限。 求对于给定的钱数N,我们最多有几种不同的找钱方式。硬币的顺序并不重要。
例如,对于N = 4,S = {1,2,3},有四种方案:{1,1,1,1},{1,1,2},{2,2},{1, 3}。所以输出应该是4。对于N = 10,S = {2,5, 3,6},有五种解决办法:{2,2,2,2,2},{2,2,3,3},{2,2,6 },{2,3,5}和{5,5}。所以输出应该是5。
1)最优子结构
要算总数的解决方案,我们可以把所有的一整套解决方案在两组 (其实这个方法在组合数学中经常用到,要么包含某个元素要么不包含,用于递推公式等等,)。
解决方案不包含 第m种硬币(或S**m)。
- 解决方案包含至少一个 第m种硬币。让数(S [] , M, N)是该函数来计算解的数目,则它可以表示为计数的总和(S [], M-1, N)和计数(S[],M,N−S**m)。
因此,这个问题具有最优子结构性质的问题。
2) 重叠子问题
下面是一个简单的递归实现硬币找零问题。遵循上面提到的递归结构。
#include<stdio.h>int count( int S[], int m, int n ){// 如果n为0,就找到了一个方案if (n == 0)return 1;if (n < 0)return 0;// 没有硬币可用了,也返回0if (m <=0 )return 0;// 按照上面的递归函数return count( S, m - 1, n ) + count( S, m, n-S[m-1] );}// 测试int main(){int i, j;int arr[] = {1, 2, 3};int m = sizeof(arr)/sizeof(arr[0]);printf("%d ", count(arr, m, 4));getchar();return 0;}
应当指出的是,上述函数反复计算相同的子问题。见下面的递归树为S = {1,2,3},且n = 5。
的函数C({1},3)被调用两次。如果我们绘制完整的树,那么我们可以看到,有许多子问题被多次调用。C() --> count()C({1,2,3}, 5)/ \/ \C({1,2,3}, 2) C({1,2}, 5)/ \ / \/ \ / \C({1,2,3}, -1) C({1,2}, 2) C({1,2}, 3) C({1}, 5)/ \ / \ / \/ \ / \ / \C({1,2},0) C({1},2) C({1,2},1) C({1},3) C({1}, 4) C({}, 5)/ \ / \ / \ / \/ \ / \ / \ / \. . . . . . C({1}, 3) C({}, 4)/ \/ \. .
所以,硬币找零问题具有符合动态规划的两个重要属性。像其他典型的动态规划(DP)的问题,可通过自下而上的方式打表,存储相同的子问题。当然上面的递归程序也可以改写成记忆化存储的方式来提高效率。
下面是动态规划的程序:
#include<stdio.h>int count( int S[], int m, int n ){int i, j, x, y;// 通过自下而上的方式打表我们需要n+1行// 最基本的情况是n=0int table[n+1][m];// 初始化n=0的情况 (参考上面的递归程序)for (i=0; i<m; i++)table[0][i] = 1;for (i = 1; i < n+1; i++){for (j = 0; j < m; j++){// 包括 S[j] 的方案数x = (i-S[j] >= 0)? table[i - S[j]][j]: 0;// 不包括 S[j] 的方案数y = (j >= 1)? table[i][j-1]: 0;table[i][j] = x + y;}}return table[n][m-1];}// 测试int main(){int arr[] = {1, 2, 3};int m = sizeof(arr)/sizeof(arr[0]);int n = 4;printf(" %d ", count(arr, m, n));return 0;}
时间复杂度:O(m**n)
以下为上面程序的优化版本。这里所需要的辅助空间为O(n)。因为我们在打表时,本行只和上一行有关,类似01背包问题。
int count( int S[], int m, int n ){int table[n+1];memset(table, 0, sizeof(table));//初始化基本情况table[0] = 1;for(int i=0; i<m; i++)for(int j=S[i]; j<=n; j++)table[j] += table[j-S[i]];return table[n];}
0-1背包问题
问题[12]:在M件物品取出若干件放在空间为W的背包里,每件物品的体积为W1,W2……W**n,与之相对应的价值为P1,P2……P**n。求出获得最大价值的方案。
注意:在本题中,所有的体积值均为整数。01的意思是,每个物品都是一个整体,要么整个都要,要么都不要。
1)最优子结构
考虑所有物品的子集合,考虑第n个物品都有两种情况: 一种情况: 包括在最优方案中 ;二 种情况:不在最优方案中。因此,能获得的最大价值,即为以下两个值中较大的那个
- 1) 在剩下 n−1个物品中(剩余 W 重量可用)的情况能得到的最大价值 (即排除了 第n个物品)
- 2) 第n个物品的价值加上剩下 剩下的 n−1 个物品(剩余W−w**n的重量)能得到的最大价值。(即包含了第n个物品)
如果第n个物品的重量,超过了当前的剩余重量W,那么只能选情况1), 排除第n个物品。
2) 重叠子问题
下面是一个递归的实现,按照上面的最优子结构。
/* 朴素的递归实现 0-1 背包 */#include<stdio.h>int max(int a, int b) { return (a > b)? a : b; }// 返回 前n个物品在容量为W时,能得到的最大价值int knapSack(int W, int wt[], int val[], int n){// 没有物品了if (n == 0 || W == 0)return 0;// 如果当前第n个物品超重了,就排除在外if (wt[n-1] > W)return knapSack(W, wt, val, n-1);//返回两种情况下最大的那个 (1) 包括第n个物品 (2) 不包括第n个物品else return max( val[n-1] + knapSack(W-wt[n-1], wt, val, n-1),knapSack(W, wt, val, n-1));}// 测试int main(){int val[] = {60, 100, 120};int wt[] = {10, 20, 30};int W = 50;int n = sizeof(val)/sizeof(val[0]);printf("%d", knapSack(W, wt, val, n));return 0;}
这种方法其实就是搜索了所有的情况,但是有很多重复的计算。时间复杂度是指数级的 O(2n)。
在下面的递归树中 K() 代表 knapSack().输入数据如下:wt[] = {1, 1, 1}, W = 2, val[] = {10, 20, 30}K(3, 2) ---------> K(n, W)/ \/ \K(2,2) K(2,1)/ \ / \/ \ / \K(1,2) K(1,1) K(1,1) K(1,0)/ \ / \ / \/ \ / \ / \K(0,2) K(0,1) K(0,1) K(0,0) K(0,1) K(0,0)
可见相同的子问题被计算多次。01背包满足动态规划算法的两个基本属性(重叠子问题和最优子结构)。可以通过自下而上的打表,存储中间结果,来避免重复计算。动态规划解法如下:
#include<stdio.h>int max(int a, int b) { return (a > b)? a : b; }int knapSack(int W, int wt[], int val[], int n){int i, w;int dp[n+1][W+1];for (i = 0; i <= n; i++){for (w = 0; w <= W; w++){if (i==0 || w==0)dp[i][w] = 0;else if (wt[i-1] <= w)dp[i][w] = max(val[i-1] + dp[i-1][w-wt[i-1]], dp[i-1][w]);elsedp[i][w] = dp[i-1][w];}}return dp[n][W];}int main(){int val[] = {80, 100, 150};int wt[] = {10, 20, 30};int W = 50;int n = sizeof(val)/sizeof(val[0]);printf("%d", knapSack(W, wt, val, n));return 0;}
空间复杂度和时间复杂度都为O(W**n). 由于打表的过程中,计算的当前行只依赖上一行,空间复杂度可以优化为O(W).
划分问题
划分问题是指有一个集合,判断是否可以把这个结合划分为总和相等的两个集合。例如:arr[] = {1, 5, 11, 5},Output: true.这个数组可以划分为: {1, 5, 5} 和 {11}. arr[] = {1, 5, 3}Output: false.无法划分为总和相等的两部分
如果划分后的两个集合总和相等,则原集合的总和肯定为偶数,假设为总和为sum。问题即为是否有子集合的总和为sum/2.
递归解决
设函数
isSubsetSum(arr, n, sum/2)返回true如果存在arr的一个子集合的总和为sum/2isSubsetSum函数为分为下面两个子问题- 1) 不考虑最后一个元素。问题递归到 isSubsetSum(arr, n-1. sum/2)
- 2) 考虑最后一个元素。问题递归到 isSubsetSum(arr, n-1. sum/2-arr[n])
上面两种情况有一个返回TRUE,即可
isSubsetSum (arr, n, sum/2) = isSubsetSum (arr, n-1, sum/2) ||isSubsetSum (arr, n-1, sum/2 – arr[n-1])
代码如下所示:
#include <iostream>#include <stdio.h>bool isSubsetSum (int arr[], int n, int sum){// 基本情况if (sum == 0)return true;if (n == 0 && sum != 0)return false;// 如果最后一个元素比sum大,就不考虑该元素if (arr[n-1] > sum)return isSubsetSum (arr, n-1, sum);//分别判断包括最后一个元素 和 不包括最后一个元素return isSubsetSum (arr, n-1, sum) || isSubsetSum (arr, n-1, sum-arr[n-1]);}bool findPartiion (int arr[], int n){int sum = 0;for (int i = 0; i < n; i++)sum += arr[i];// 奇数不可能划分if (sum%2 != 0)return false;return isSubsetSum (arr, n, sum/2);}// 测试int main(){int arr[] = {3, 1, 5, 9, 12};int n = sizeof(arr)/sizeof(arr[0]);if (findPartiion(arr, n) == true)printf("Can be divided into two subsets of equal sum");elseprintf("Can not be divided into two subsets of equal sum");return 0;}
时间复杂度:最快情况为 O(2n),即每个元素有选或不选的两种选择
动态规划
如果所有元素的总和sum不是特别大时可以用动态规划来解决。问题可以转化为 是否有子集合的总和为sum/2.
这里通过自下向上打表的方法来记录子问题的解, part[i][j] 表示对于子集合 {arr[0], arr[1], ..arr[j-1]} 其总和是否为i.其实这个问题和01背包问题是一样的。背包的最大容量为sum/2,如果最大价值可以达到sum/2则返回TRUE。
bool findPartiion (int arr[], int n){int sum = 0;int i, j;for (i = 0; i < n; i++)sum += arr[i];if (sum%2 != 0)return false;bool part[sum/2+1][n+1];for (i = 0; i <= n; i++)part[0][i] = true;for (i = 1; i <= sum/2; i++)part[i][0] = false;for (i = 1; i <= sum/2; i++){for (j = 1; j <= n; j++){part[i][j] = part[i][j-1];if (i >= arr[j-1])part[i][j] = part[i][j] || part[i - arr[j-1]][j-1];}}/** //测试打表数据for (i = 0; i <= sum/2; i++){for (j = 0; j <= n; j++)printf ("%4d", part[i][j]);printf("\n");} */return part[sum/2][n];}
时间复杂度为 O(sum*n)
二项式系数
以下是常见的二项式系数的定义:
- 1) 一个二项式系数C(n,k) 可以被定义为(1+X)n 的展开式中 X**k 的系数。
- 2) 二项式系数对组合数学很重要,因它的意义是从n件物件中,不分先后地选取k件的方法总数,因此也叫做组合数.
问题[13]: 写一个函数,它接受两个参数n和k,返回二项式系数C(n,k)。例如,你的函数应该返回6 当n = 4 k = 2时,返回10当 n = 5 k = 2时。
1) 最优子结构
C(n,k)的值可以递归地使用以下标准公式计算,这个应该是:
C(n,k)=C(n−1,k−1)+C(n−1,k)
C(n,0)=C(n,n)=12) 重叠子问题
下面是一个直接用上面的公式写的递归程序解决:
// 直接递归实现#include<stdio.h>// 返回二项式系数的值 C(n, k)int binomialCoeff(int n, int k){// 基本情况if (k==0 || k==n)return 1;// Recurreturn binomialCoeff(n-1, k-1) + binomialCoeff(n-1, k);}/* 测试程序 */int main(){int n = 5, k = 2;printf("Value of C(%d, %d) is %d ", n, k, binomialCoeff(n, k));return 0;}
应该指出的是,上面的程序一次又一次计算相同的子问题。看到下面的递归树n = 5 k = 2。函数C(3,1)执行两次。对于较大的n 值,将会有许多共同的子问题。
C(5, 2)/ \C(4, 1) C(4, 2)/ \ / \C(3, 0) C(3, 1) C(3, 1) C(3, 2)/ \ / \ / \C(2, 0) C(2, 1) C(2, 0) C(2, 1) C(2, 1) C(2, 2)/ \ / \ / \C(1, 0) C(1, 1) C(1, 0) C(1, 1) C(1, 0) C(1, 1)
很明显,这个问题可以用动态规划来解决,因为包含了动态规划的两个基本属性(见重叠子问题和最优子结构)
和经典的动态规划解决办法一样,这里通过自下而上的构建数组 C[][] 保存子问题的值。
#include<stdio.h>int min(int a, int b);// 返回二项式系数 C(n, k)int binomialCoeff(int n, int k){int C[n+1][k+1];int i, j;// 通过自下而上的方式打表for (i = 0; i <= n; i++){for (j = 0; j <= min(i, k); j++){if (j == 0 || j == i)C[i][j] = 1;elseC[i][j] = C[i-1][j-1] + C[i-1][j];}}return C[n][k];}int min(int a, int b){return (a<b)? a: b;}/* 测试程序*/int main(){int n = 5, k = 2;printf ("Value of C(%d, %d) is %d ", n, k, binomialCoeff(n, k) );return 0;}
时间复杂度: O(n*k)
空间复杂度: O(n*k)其实,空间复杂度可以优化到 O(k). 但是实际应用中,还是直接用二维数组打表使用比较多。
// 空间优化int binomialCoeff(int n, int k){int* C = (int*)calloc(k+1, sizeof(int));int i, j, res;C[0] = 1;for(i = 1; i <= n; i++){for(j = min(i, k); j > 0; j--)C[j] = C[j] + C[j-1];}res = C[k]; // 在释放内存前存储结果free(C);return res;}
参考资料
- 算法导论CLRS
- Optimal substructureFrom Wikipedia, the free encyclopedia .
- Floyd–Marshall algorithm From Wikipedia, the free encyclopaedia.
- Bellman–Ford algorithmFrom Wikipedia, the free encyclopaedia.
- Longest Increasing Subsequence
- Longest Common Subsequence
- Dyanamic programming :Longset common subsequence
- Long palindromic Subsequence
- Lucene From Wikipedia, the free encyclopedia
- Coin Change from geeksforgeeks
- Coin Change from algorithms.com
- 0-1 knapsack problem
- Binomial coefficient
































还没有评论,来说两句吧...