Lucene
什么是Lucene
- Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
- Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具
- Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品
- 官网:http://lucene.apache.org/
用idea写代码
- 创建maven项目(new—project——maven)
添加依赖(pom.xml)

4.10.2
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><!-- lucene核心库 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>${lunece.version}</version></dependency><!-- Lucene的查询解析器 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>${lunece.version}</version></dependency><!-- lucene的默认分词器库 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>${lunece.version}</version></dependency><!-- lucene的高亮显示 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>${lunece.version}</version></dependency>
</dependencies>
3.在idea下的这个文件里新建class
import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;import org.junit.Test;import java.io.File;public class lucencetest {//创建索引@Testpublic void testCreate() throws Exception{//1、创建文档对象Document document =new Document();// 创建并添加字段信息。参数:字段的名称、字段的值、是否存储,这里选Store.YES代表存储到文档列表。Store.NO代表不存储document.add(new StringField("id", "1", Field.Store.YES));// 这里我们title字段需要用TextField,即创建索引又会被分词。StringField会创建索引,但是不会被分词document.add(new TextField("title","谷歌地图之父跳槽facebook", Field.Store.YES));//2 索引目录类,指定索引在硬盘中的位置Directory directory = FSDirectory.open(new File("d:\\indexDir"));//3 创建分词器对象Analyzer analyzer = new StandardAnalyzer();//4 索引写出工具的配置对象IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);//5 创建索引的写出工具类。参数:索引的目录和配置信息IndexWriter indexWriter = new IndexWriter(directory, conf);//6 把文档交给IndexWriterindexWriter.addDocument(document);//7 提交indexWriter.commit();//8 关闭indexWriter.close();}}
点击运行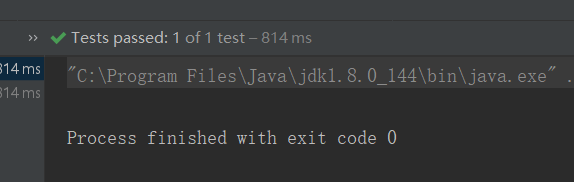
查看d盘下,是否有你所创建的文件夹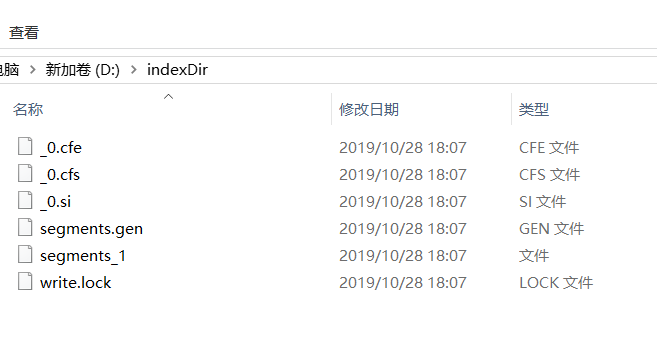
也可以创建多条文档的文件
现在pom.xml添加<!-- https://mvnrepository.com/artifact/com.janeluo/ikanalyzer --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency>依赖
import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.File;import java.util.ArrayList;public class lucencebb {@Testpublic void testCreate2() {try {ArrayList<Document> documents = new ArrayList<Document>();Document document = new Document();document.add(new StringField("id","1", Field.Store.YES));document.add(new TextField("title","谷歌地图之父跳槽facebook",Field.Store.YES));documents.add(document);Document document2 = new Document();document2.add(new StringField("id","2",Field.Store.YES));document2.add(new TextField("title","谷歌地图之父加盟FaceBook",Field.Store.YES));documents.add(document2);Document document3 = new Document();document3.add(new StringField("id","3",Field.Store.YES));document3.add(new TextField("title","谷歌地图创始人拉斯离开谷歌加盟Facebook",Field.Store.YES));documents.add(document3);Document document4 = new Document();document4.add(new StringField("id","4",Field.Store.YES));document4.add(new TextField("title","谷歌地图之父跳槽Facebook与Wave项目取消有关",Field.Store.YES));documents.add(document4);Document document5 = new Document();document5.add(new StringField("id","5",Field.Store.YES));document5.add(new TextField("title","谷歌地图之父拉斯加盟社交网站Facebook",Field.Store.YES));documents.add(document5);FSDirectory dir = FSDirectory.open(new File("d:/lucenedata"));IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);IndexWriter indexWriter = new IndexWriter(dir, conf);indexWriter.addDocuments(documents);indexWriter.commit();indexWriter.close();} catch (Exception e) {e.printStackTrace();}}}
同样运行,查看
4.运行查询代码
import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;import java.io.File;public class tabletest {@Testpublic void testSearch() throws Exception {// 索引目录对象Directory directory = FSDirectory.open(new File("d:\\lucenedata"));// 索引读取工具IndexReader reader = DirectoryReader.open(directory);// 索引搜索工具IndexSearcher searcher = new IndexSearcher(reader);// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器QueryParser parser = new QueryParser("title", new IKAnalyzer());// 创建查询对象Query query = parser.parse("谷歌");// 搜索数据,两个参数:查询条件对象要查询的最大结果条数// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。TopDocs topDocs = searcher.search(query, 10);// 获取总条数System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {// 取出文档编号int docID = scoreDoc.doc;// 根据编号去找文档Document doc = reader.document(docID);System.out.println("id: " + doc.get("id"));System.out.println("title: " + doc.get("title"));// 取出文档得分System.out.println("得分: " + scoreDoc.score);}}}
查询结果:
"C:\Program Files\Java\jdk1.8.0_144\bin\java.exe" -ea -Didea.test.cyclic.buffer.size=1048576 "-javaagent:F:\idea2019\IntelliJ IDEA 2019.1.3\lib\idea_rt.jar=52601:F:\idea2019\IntelliJ IDEA 2019.1.3\bin" -Dfile.encoding=UTF-8 -classpath "F:\idea2019\IntelliJ IDEA 2019.1.3\lib\idea_rt.jar;F:\idea2019\IntelliJ IDEA 2019.1.3\plugins\junit\lib\junit-rt.jar;F:\idea2019\IntelliJ IDEA 2019.1.3\plugins\junit\lib\junit5-rt.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_144\jre\lib\rt.jar;F:\idea2019\Luceneaa\target\test-classes;C:\Users\ABU\.m2\repository\junit\junit\4.12\junit-4.12.jar;C:\Users\ABU\.m2\repository\org\hamcrest\hamcrest-core\1.3\hamcrest-core-1.3.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-core\4.10.2\lucene-core-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-queryparser\4.10.2\lucene-queryparser-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-queries\4.10.2\lucene-queries-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-sandbox\4.10.2\lucene-sandbox-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-analyzers-common\4.10.2\lucene-analyzers-common-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-highlighter\4.10.2\lucene-highlighter-4.10.2.jar;C:\Users\ABU\.m2\repository\org\apache\lucene\lucene-memory\4.10.2\lucene-memory-4.10.2.jar;C:\Users\ABU\.m2\repository\com\janeluo\ikanalyzer\2012_u6\ikanalyzer-2012_u6.jar" com.intellij.rt.execution.junit.JUnitStarter -ideVersion5 -junit4 tabletest,testSearch本次搜索共找到5条数据id: 1title: 谷歌地图之父跳槽facebook得分: 0.35773432id: 2title: 谷歌地图之父加盟FaceBook得分: 0.35773432id: 3title: 谷歌地图创始人拉斯离开谷歌加盟Facebook得分: 0.289093id: 5title: 谷歌地图之父拉斯加盟社交网站Facebook得分: 0.25552452id: 4title: 谷歌地图之父跳槽Facebook与Wave项目取消有关得分: 0.20441961Process finished with exit code 0


































还没有评论,来说两句吧...